BAG: Body-Aligned 3D Wearable Asset Generation
Abstract

While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality.
Overview
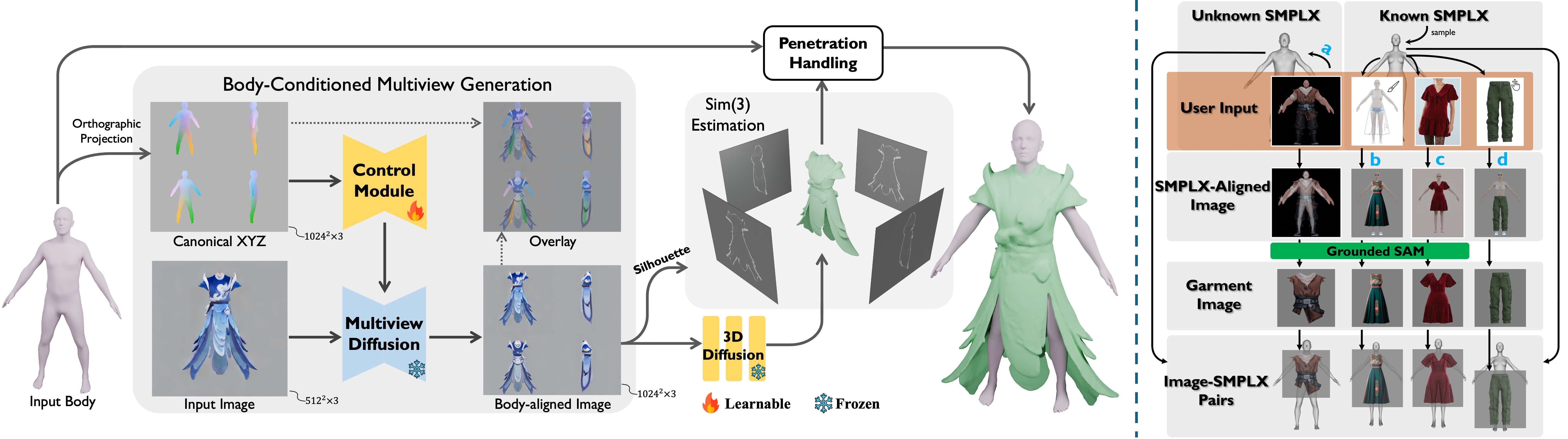
The pipeline of our proposed method: As seen in the left figure, given an input image and a target body, we employ body-conditioned image generation to produce body-aligned consistent four-view orthographic images. The four-view images are then fed into a native 3D diffusion model to obtain the asset shape.The similarity transformation (Sim3) of the generated asset is estimated through silhouette-based projection optimization. Finally, after solving the body-asset penetration, the Sim3-transformed asset is fitted onto the human body. As seen in the right figure, there are four methods to acqure input body and image pairs. (a) SMPLX Fitting. (b)Sketch-Based Modeling. (c) Virtual Try-on. (d) Manual Images Assembly.
Sim(3) Estimation: Due to the non-deterministic nature of the diffusion model, the shape generator cannot guarantee that the output shape will align with the input multi-view images. This misalignment can manifest as differences in scale, translation, and rotation. To address this issue, we apply the Similarity Transformation Estimation.
Asset-Body Penetration Handling: The Sim(3)-transformed asset can roughly align with the body, but small penetrations between the asset and body still exist. To address this issue, we further resolve such penetrations using a physics simulation-based solver.
Result Gallery

Result gallery across four settings: (a) Single-view reconstruction with fitted SMPLX; (b) Image-Based Virtual Try-On; (c) Assembling existing 2D assets; and (d) Sketch-Based modeling. Each image is followed by the reconstructed asset mesh. Our method demonstrates proficiency in effectively producing body-aligned asset shapes and faithfully capturing high-fidelity geometric details from the input.
Comparison with Baseline
As observed, BCNet, ClothWild and SewFormer fail to generate results that align with the input image. This limitation stems from their sole reliance on garment parametric models (whether explicit, implicit, or based on sewing patterns). The limited representational capacity of these parametric models hinders their ability to recover aligned garment shapes that accurately follows the input images. Although Frankenstein employs a more effective 3D triplane representation, its stringent requirements for training data make it difficult to scale up. The limited availability of data results in inadequate generalization capabilities of the trained model, hindering its ability to effectively reconstruct complex garments from images. By harnessing the advanced generalization capabilities of large 3D models, Garment3DGen can reconstruct relatively aligned 3D shapes from images. However, due to the lack of prior knowledge about body shapes, the generated 3D garments are challenging to fit onto the human body, which necessitates labor-intensive and time-consuming manual post-processing to achieve body-garment alignment. Furthermore, its template-fitting method restricts topological flexibility, obstructing the recovery of complex structures and fine-grained geometric details. Our method demonstrates proficiency in effectively producing body-aligned garment shapes and faithfully capturing high-fidelity geometric details from single-view images.
Ablation Study of Body-aligned Multi-View Generation
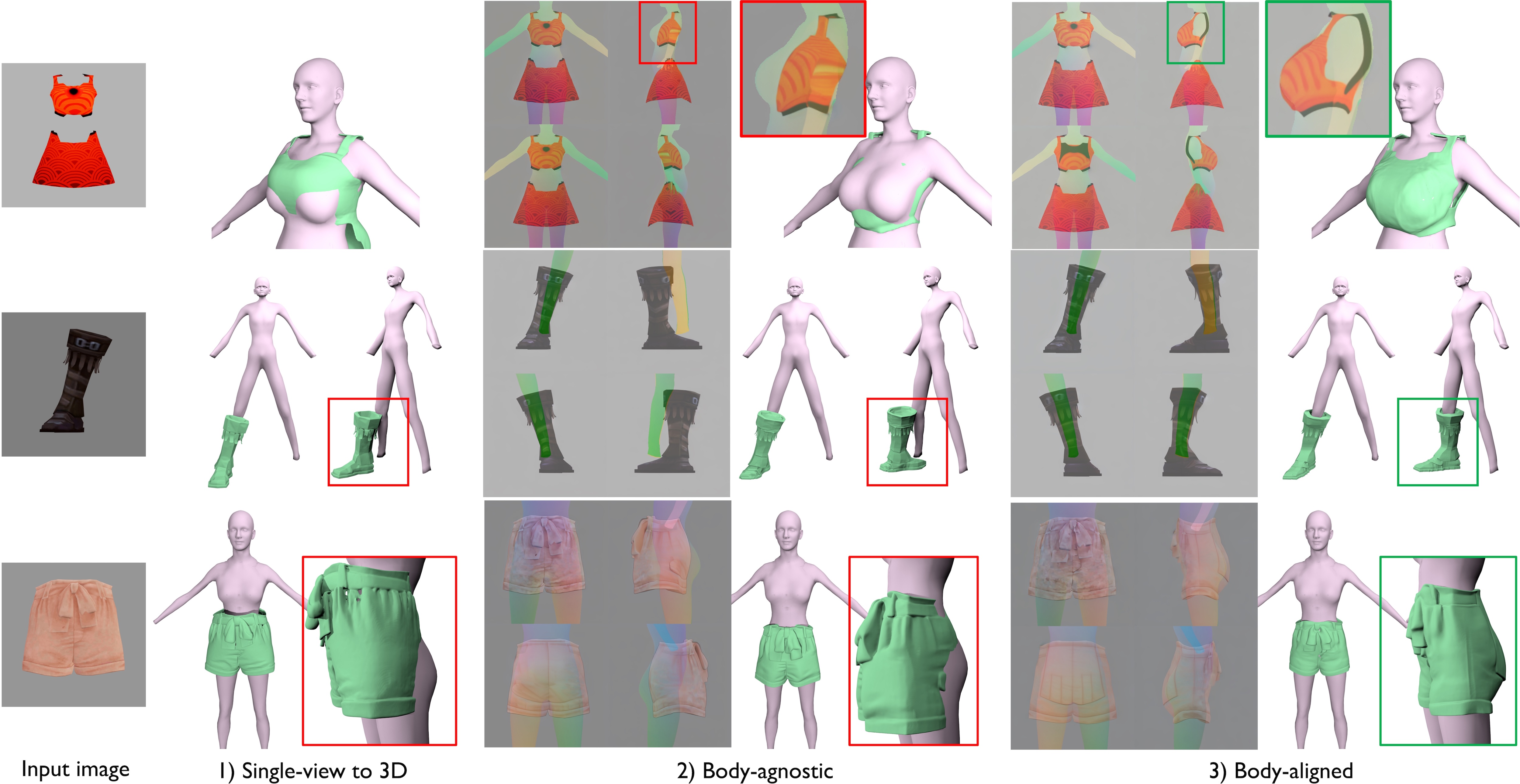
As observed, both the single-view and body-agnostic multi-view approaches result in body-garment misalignment. The lack of depth information in the single-view to 3D asset method often leads to discrepancies in depth between the body and the asset. The absence of body conditioning in the original multi-view generation yields multi-view images that misalign with the corresponding 2D body renderings, causing noticeable offsets between the generated multi-view images and the body renderings. In contrast, our body-aligned multi-view image generation guarantees precise alignment of assets with the human body across multiple perspectives, ensuring that the final generated 3D assets are consistently aligned with the 3D body.
Ablation Study of Alignment Strategy
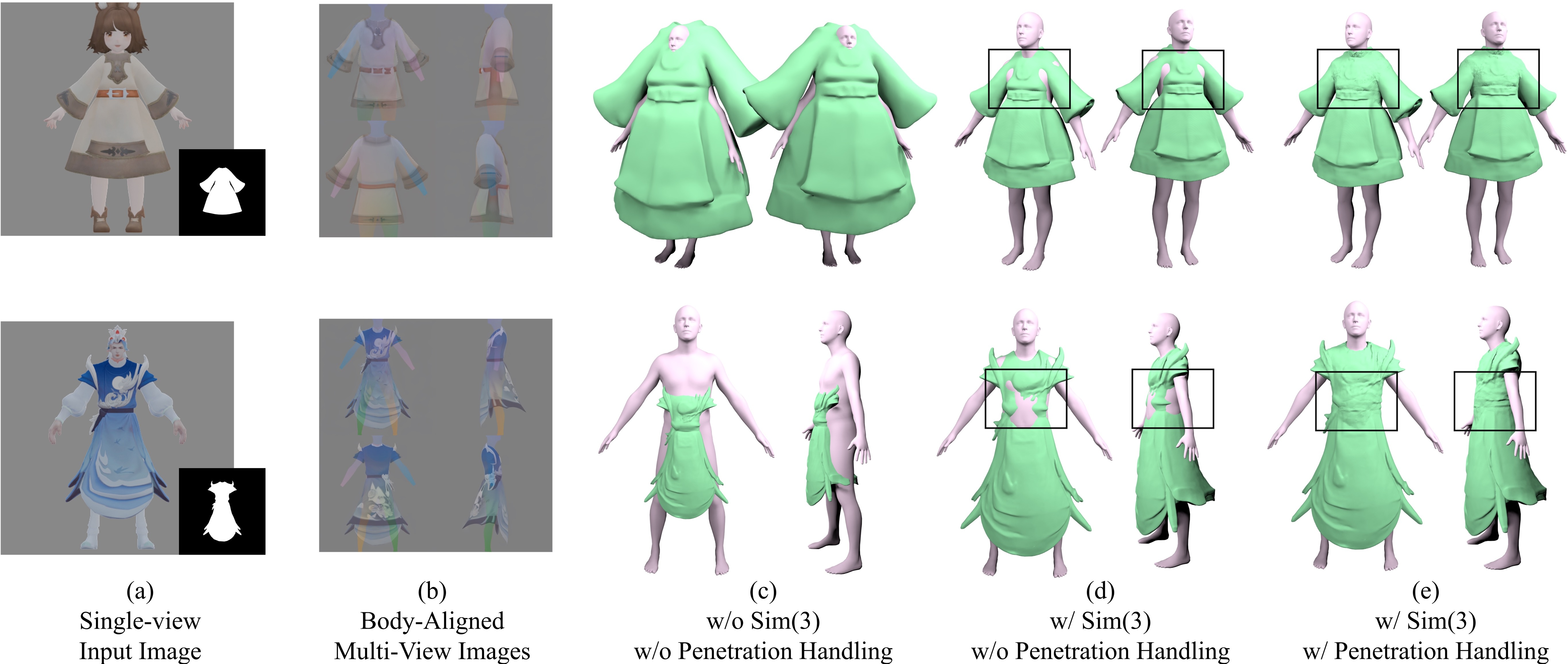
Qualitative comparison between ours and the ablated alignement strategies. As shown, while the generated multi-view images align with the rendered body from various 2D perspectives (b), the generated 3D assets do not effectively guarantee alignment with the input images (c). This discrepancy stems from different techniques and normalization strategies used in multiview-to-3D diffusion models. By employing Sim(3) optimization, the 3D mesh aligns with the human body (d), though some penetrations remain. Our penetration-handling approach, as illustrated in (e), achieves a penetration-free state for the asset and the body.
Application: Asset Retargeting
Application: Animation